Bem vindo ao meu novo artigo! Neste artigo pretendo escrever sobre o teste de normalidade de Kolmogorov-Smirnov e como substituir o CSE (Control+Shift+Enter) na suas planilhas.
Este teste "resulta" a máxima diferença absoluta entre a função de distribuição acumulada assumida para os dados, neste artigo vamos demonstrar a aplicação com três distribuições, sendo a distribuição normal, a distribuição gama e a lognormal. Como resposta, comparamos o valor crítico (Dcrítico), para um dado nível de significância da tabela de Kolmogorov-Smirnov, para ser aceito ou não os dados em uma distribuição,
Vamos aos dados abaixo:
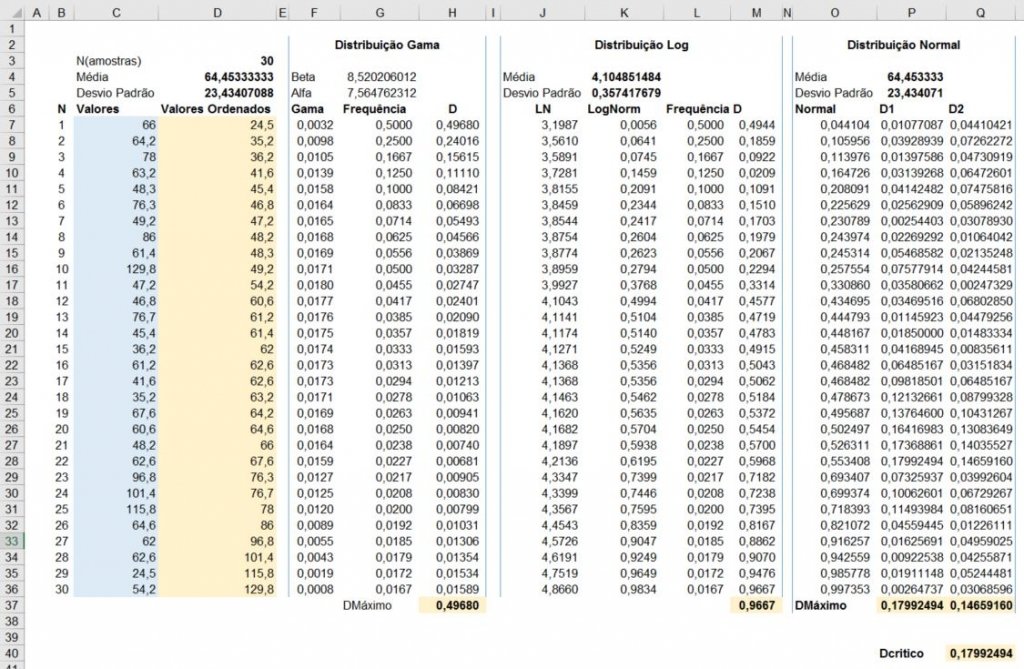
Neste exemplo acima fiz um modelo estático para uma série com 30 valores.
Primeiro passo será deixar os dados de maneira crescente, para isso utilizei a fórmula nas células D7:D36, segue abaixo:
=MENOR($C$7:$C$36;LINS($D$7:D7))ou em inglês
=SMALL($C$7:$C$36;ROWS($D$7:D7))Precisaremos obter a quantidade de registros, que segue a fórmula na célula D3
=CONT.NÚM(D7:D36)ou em inglês
=COUNT(D7:D36)Devemos calcular a Média dos nossos dados e Desvio Padrão, vamos as fórmulas:
Média - Célula D4:
=MÉDIA(D7:D36)ou em inglês
=AVERAGE(D7:D36)Desvio Padrão - Célula D5
=DESVPAD(D7:D36)ou em inglês
=STDEV(D7:D36)Com os dados calculados, teremos que calcular os "Dcríticos" em comparação as distribuições desejadas, neste artigo irei descrever três tipos de Distribuições, mas você poderá aplicar a qualquer distribuição que você deseja.
Vamos a primeira distribuição:
Distribuição Gama
Nesta distribuição é necessário cálcular o Alfa e Beta que estão nas células G5 e G4, vamos aos cálculos
Cálculo de Beta: Será o ((Desvio Padrão)^2)/Média
=(D5^2)/D4Cálculo de Alfa: Será a Média/Beta
=D4/G4Agora vamos inserir o cálculo da distribuição gama nas células F7:F36, segue a fórmula:
=DIST.GAMA($D7;$G$5;$G$4;0)ou em inglês
=GAMMA.DIST($D7;$G$5;$G$4;0)Teremos que calcular a frequência que segue a formula nas células G7:G36:
=(1-0,5)/B7Com essas duas colunas podemos agora calcular o Dcrítico que segue nas células H7:H36
=ABS(F7-G7)Para finalizar precisaremos achar o maior valor entre as células H7:H36, para isso utilizamos a fórmula abaixo (célula H37):
=MÁXIMO(H7:H36)ou em inglês
=MAX(H7:H36)No estudo observado resultou em 0,496800564250527, vamos reservar esse número para utilizar nas comparações finais.
Distribuição LogNormal
Nesta distribuição teremos que aplicar a fórmula do logaritmo natural a série ordenada, e com isso calcular nova média e novo desvio padrão dos dados "transformados" vamos aos cálculos:
Primeiro teremos transformar os nossos dados nas células J7:J36 utilizando a fórmula abaixo:
=LN(D7)Com a coluna criada teremos que calcular a nossa Média (célula K4), que segue abaixo
=MÉDIA(J7:J36)ou em inglês
=AVERAGE(J7:J36)e o Desvio Padrão (célula K5), que segue abaixo
=DESVPAD(J7:J36)ou em inglês
=STDEV(J7:J36)Agora aplicando a fórmula da Distribuição LogNormal nas células K7:K36,
=DIST.LOGNORMAL(D7;$K$4;$K$5)ou em inglês
=LOGNORMDIST(D7;$K$4;$K$5)Também teremos que calcular a frequência que segue nas células L7:L36
=(1-0,5)/$B7E por último cálcular o Dcrítico que segue nas células M7:M36
=ABS(K7-L7)Com os dados dos "Dcríticos" aplicamos a fórmula para resultar a maior diferença que segue abaixo (célula M37):
=MÁXIMO(M7:M36)ou em inglês
=MAX(M7:M36)Nesta amostra aplicada a estra distribuição resultou o valor de 0,966729462424326.
Distribuição Normal
Nesta distribuição teremos que aplicar com dois "Dcríticos" e para a escolha deveremos obter o entre eles, mas vamos aos cálculos
Cálculo da distribuição normal, segue nas células O7:O36
=DIST.NORM.N(D7;$D$4;$D$5;1)ou em inglês
=NORM.DIST(D7;$D$4;$D$5;1)Agora calculando direto o primeiro "Dcrítico" com sua frequência, que segue na célula P7:P36
=ABS(O7-(B7/$D$3))E segue o cálculo do segundo "Dcrítico" com sua frequência, que segue na célula Q7:Q36
=ABS(O7-(B7-1)/$D$3)A diferença entre elas é que uma é calculada com a frequência da serie e outra com uma defasagem de 1 intervalo.
Após o cálculo dos dois "Dcríticos" o resultado será o maior valor, segue na célula Q40
=MÁXIMO(MÁXIMO(P7:P36);MÁXIMO(Q7:Q36))ou em inglês
=MAX(MAX(P7:P36);MAX(Q7:Q36))Para a distribuição normal resultou o valor de 0,179924935721853
Com os três valores calculados teremos que comparar com a tabela de amostras vs nível de significância
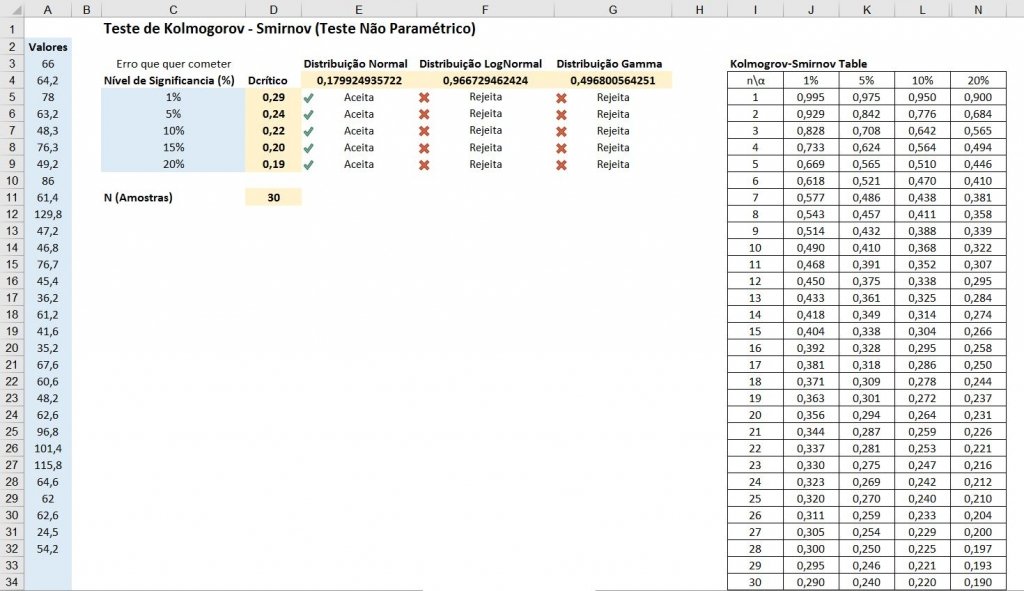
Na tabela teremos que informar a quantidade de amostras, que temos neste caso são 30 valores, e obter os valores na tabela, segue as fórmulas nas células D5:D9
=DESLOC($I$4;CORRESP($D$11;$I$5:$I$46;0);CORRESP(C5;$J$4:$N$4;0))ou em inglês
=OFFSET($I$4;MATCH($D$11;$I$5:$I$46;0);MATCH(C5;$J$4:$N$4;0))Pronto! Se o valor da Distribuição for menor do que ao da tabela com o seu nível de significância você aceita, neste caso a nossa amostra ela é aceita para a Distribuição Normal com 1% de Nível de Significância (erro que você quer cometer).
Pronto! Se o valor da Distribuição for menor do que ao da tabela com o seu nível de significância você aceita, neste caso a nossa amostra ela é aceita para a Distribuição Normal com 1% de Nível de Significância (erro que você quer cometer).
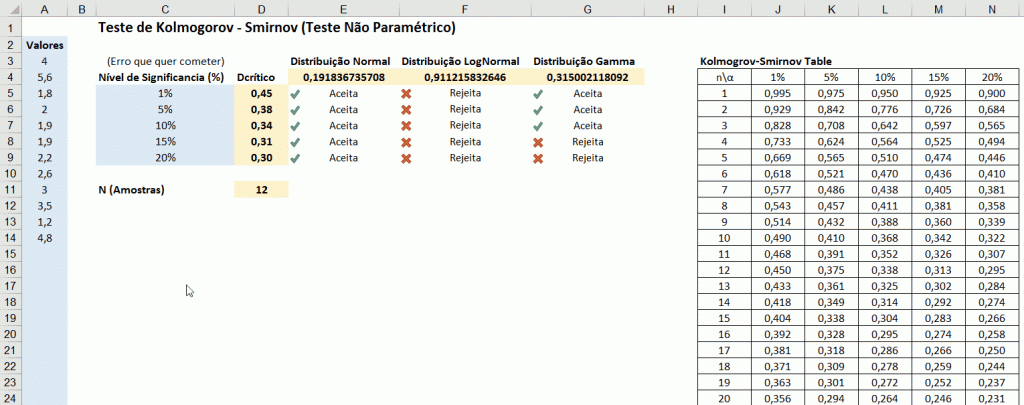
Fonte Wikipédia
Caso você queria fazer todos esses cálculos em somente uma célula e dinâmico
Segue:
Distribuição Normal - Célula E4
=MÁXIMO(MÁXIMO(ÍNDICE(ABS(DIST.NORM.N(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A))));MÉDIA(ÍNDICE(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A))));0));DESVPAD(ÍNDICE(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A))));0));1)-(LIN(INDIRETO("1:"&CONT.NÚM(A:A)))/CONT.NÚM(A:A)));0));MÁXIMO(ÍNDICE(ABS(DIST.NORM.N(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A))));MÉDIA(ÍNDICE(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A))));0));DESVPAD(ÍNDICE(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A))));0));1)-(LIN(INDIRETO("1:"&CONT.NÚM(A:A)))-1)/CONT.NÚM(A:A));0)))ou em inglês
=MAX(MAX(INDEX(ABS(NORM.DIST(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A))));AVERAGE(INDEX(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A))));0));STDEV(INDEX(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A))));0));1)-(ROW(INDIRECT("1:"&COUNT(A:A)))/COUNT(A:A)));0));MAX(INDEX(ABS(NORM.DIST(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A))));AVERAGE(INDEX(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A))));0));STDEV(INDEX(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A))));0));1)-(ROW(INDIRECT("1:"&COUNT(A:A)))-1)/COUNT(A:A));0)))Distribuição LogNormal - célula F4
=MÁXIMO(ÍNDICE(ABS(ÍNDICE(DIST.LOGNORMAL(ÍNDICE(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A))));0);MÉDIA(ÍNDICE(LN(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A)))));0));DESVPAD(ÍNDICE(LN(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A)))));0)));0)-ÍNDICE((1-0,5)/LIN(INDIRETO("1:"&CONT.NÚM(A:A)));0));0))ou em inglês
=MAX(INDEX(ABS(INDEX(LOGNORMDIST(INDEX(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A))));0);AVERAGE(INDEX(LN(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A)))));0));STDEV(INDEX(LN(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A)))));0)));0)-INDEX((1-0,5)/ROW(INDIRECT("1:"&COUNT(A:A)));0));0))Distribuição Gama - célula G4
=MÁXIMO(ABS(ÍNDICE(DIST.GAMA(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A))));MÉDIA(ÍNDICE(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A))));0))/((DESVPAD(ÍNDICE(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A))));0))^2)/MÉDIA(ÍNDICE(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A))));0)));(DESVPAD(ÍNDICE(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A))));0))^2)/MÉDIA(ÍNDICE(MENOR(DESLOC(A1;PROC(2;1/(A:A);LIN(A:A))-CONT.NÚM(A:A);0;CONT.NÚM(A:A);1);LIN(INDIRETO("1:"&CONT.NÚM(A:A))));0));0);0)-ÍNDICE((1-0,5)/(LIN(INDIRETO("1:"&CONT.NÚM(A:A))));0)))ou em inglês
=MAX(ABS(INDEX(GAMMA.DIST(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A))));AVERAGE(INDEX(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A))));0))/((STDEV(INDEX(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A))));0))^2)/AVERAGE(INDEX(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A))));0)));(STDEV(INDEX(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A))));0))^2)/AVERAGE(INDEX(SMALL(OFFSET(A1;LOOKUP(2;1/(A:A);ROW(A:A))-COUNT(A:A);0;COUNT(A:A);1);ROW(INDIRECT("1:"&COUNT(A:A))));0));0);0)-INDEX((1-0,5)/(ROW(INDIRECT("1:"&COUNT(A:A))));0)))Vamos para a curiosidade do artigo.
Quando estamos realizando uma fórmula e não quer deixar em várias células Ex:
=MÁXIMO(ABS(F7:F36-G7:G36))ou em inglês
=MAX(ABS(F7:F36-G7:G36))Se você terá que apertar o CSE (Control+Shift+Enter) para funcionar, onde irá te retornar o valor, mas como não gosto de ficar ativando o CSE e muitas pessoas ainda desconhecem a ativação matricial das fórmulas, podemos incrementar uma fórmula poderosa onde muitos desconhecem a aplicação dela que é o "ÍNDICE"!
Adicionando a fórmula ÍNDICE( INDEX em inglês) no lugar correto irá resultar o mesmo resultado e sem precisar ativar o CSE veja no exemplo abaixo
=MÁXIMO(ÍNDICE(ABS(F7:F36-G7:G36);0))Ou em inglês
=MAX(INDEX(ABS(F7:F36-G7:G36);0))Onde irá funcionar sem a ativação do CSE!
Se você gostou, clique em curtir ou compartilhe esse artigo.
E mais uma vez, vamos ao desafio! Caso este artigo tenha 100 compartilhamentos vou disponibilizar os arquivos para download!
Abraços e espero que você tenha gostado deste artigo!
Fabio BALDINI
Frase do dia: Filme menina de Ouro "Há uma magia em tentar superar os próprios limites. É a sensação de arriscar tudo por um sonho que só você vê."







{kind=link}
Link permanente
gostei, show de bola
Link permanente
Excelente!
Só foi necessário um pequeno ajuste para a fórmula da normalidade de ROW(A:A) para LIN(A:A);
Para a log normal foi necessário ajustar a formula de DISTLOGNORMAL para DIST.LOGNORMAL e funcionaram muito bem.
Link permanente
Obrigado Diovani, códigos ajustados, Abraços